
Cross-Domain Human Action Recognition from Multiview Motion and Textual Descriptions
ICPR, 2026
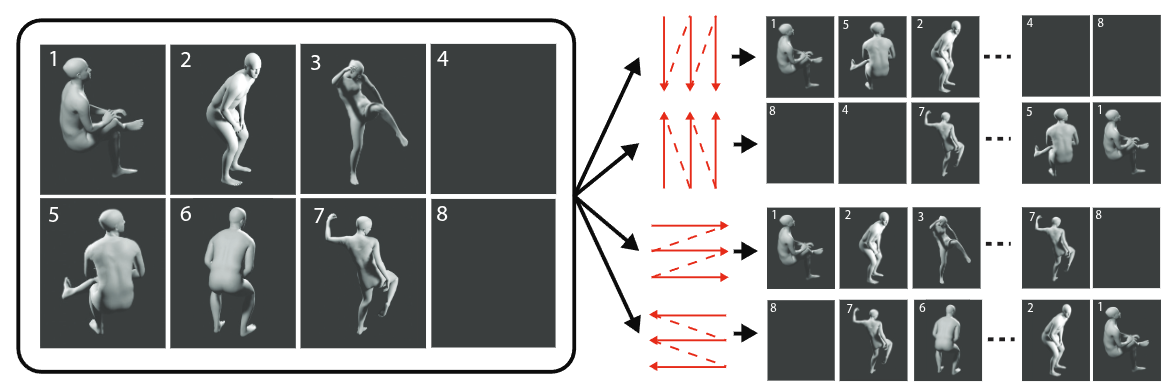
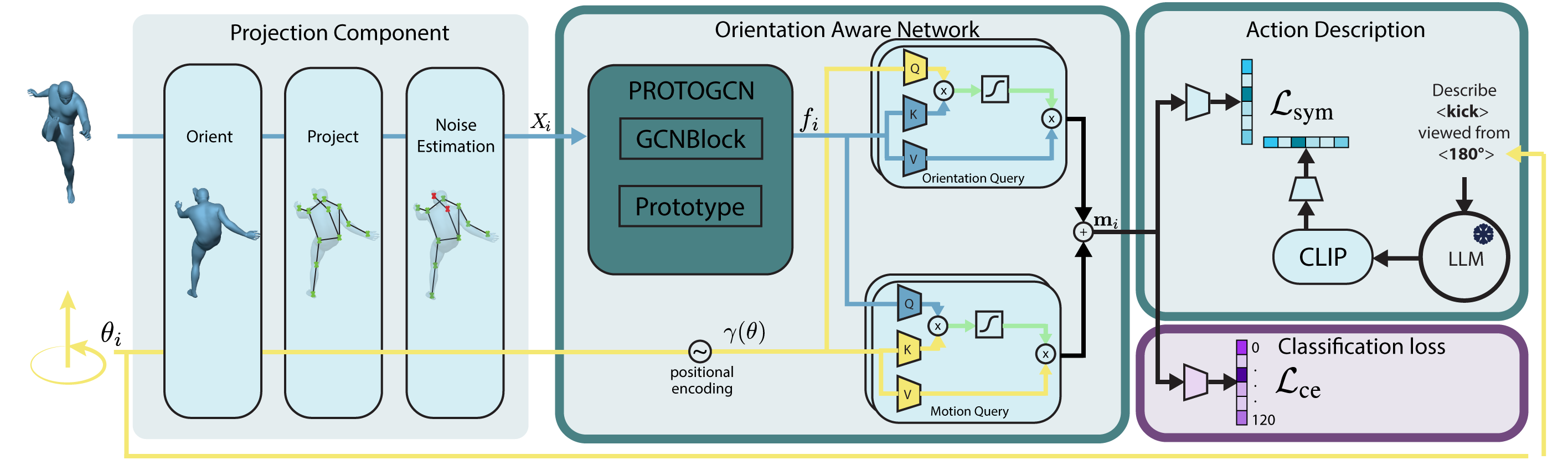
Motion to text association with motion cues of multiple camera viewpoints and textual descriptions of human actions in the training phase to handle geometric domain gaps between the training and test sets.